
Posted on November 1, 2024
One billion row challenge in C#
Back in January 2024, a few mad lads in the Java community launched the One Billion Row Challenge. This extremely interesting proposition sent shock waves through the dev community and soon a score board was publish with the fastest solutions on top.
The idea is very simple: to process a text file with a list of weather stations and temperatures and output the min, max and average of each station. Sounds simple, right? The catch is that the file has 1 billion rows and more than 13Gb. Despite this interesting twist, soon the leader board was published with some ridiculous, unbelievable and absolutely impressive <2s processing times.
Naturally other coding communities wanted a piece of the fun, and soon the challenge was solved in several different languages, as seen at 1brc.dev. Of course .NET was no exception and a leader board for C#/F# implementations was soon put in place.
I’ve started coding in C# only a couple of years ago, but I had worked with file processing and data importation before, so this challenge really caught my eyes. I was late to the race and incredible solutions have already made their way to the leader board. Impressive results (below 2s!) were achieved using unsafe and some template magic that I’m not even familiar with. But I didn’t want to use unsafe. I come from a C++ background and I like the memory safety that C# provides, therefore here’s my “vanilla c#” solution:
The solution
Found at: https://github.com/tiagorosolen/1brc
My first attempt was a simple loop, which I also use to generate the “check data” that would be used later to validate my attempts. The first solution ran for 5 minutes 52 seconds! The challenge was starting to show its paws.. The loop worked alright but it went through the file line by line, which means that the whole file had to first be loaded into RAM.
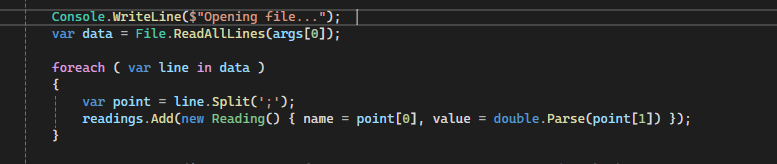
This not only took forever and a day to complete but I also dislike the ridiculous use of memory. The variable “data” is basically using 13gb of RAM, and that’s beyond unacceptable.
To solve the memory issue, in my second attempt, I tried to read byte by byte and assemble each line on my own. This reduces the processing time a little bit (still 4+ minutes) but had the great advantage of working without increasing memory usage.
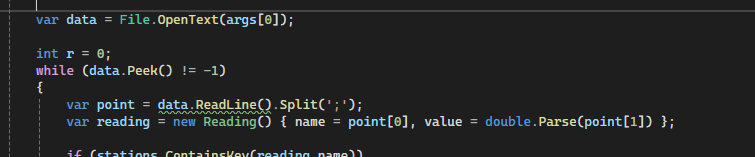
Multi Threading
The next step was to split the work into N threads, where N is the number of processor threads in the system. For that a dictionary with starting and stopping bytes had to be populated for each processor, which sounds easy, but there’s an important caveat: the data must end in a break-line, or the block would be incomplete. So this code was added that not only split the data into N CPUs, but also finds the next end line of each block.
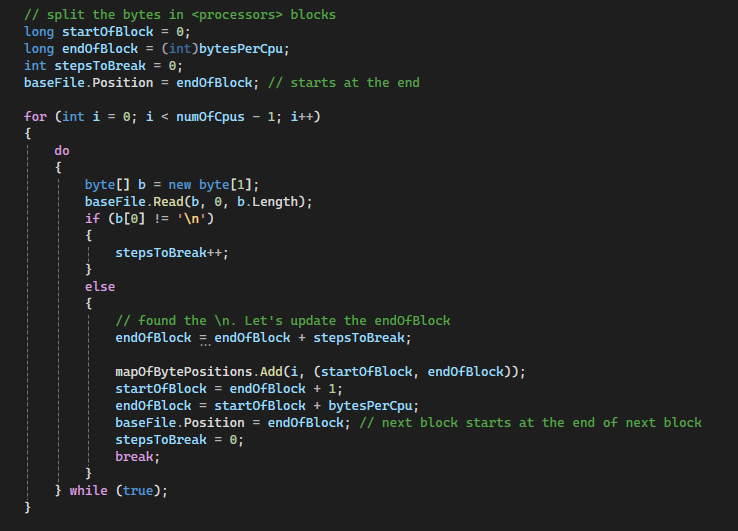
Now the file has been not only split into N processors, but each block corresponds to a integer number of lines. The block with its start-end bytes is stored into a dictionary:
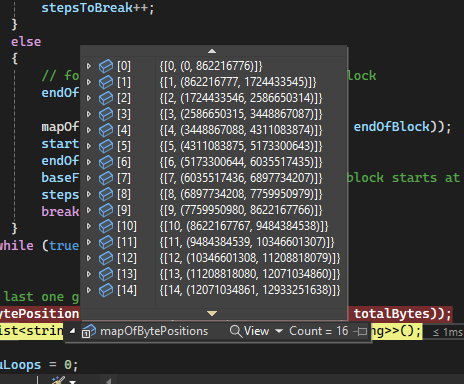
At this point, the solution was running in an acceptable 1 minute. The algorithm has 3 main parts:
- the memory split dictionary thingy
- The async function that process the file
- A sort of reassemble function that put the results of all threads together at the end.
The first and third functions can do their job almost instantaneous, I mean, within a few milliseconds. Which means that from now on my attempts of improvement would be focused on the “async/file read/data processing” function.
Optimization
At this point the solution is processing the file in about 50s, but there are still some things I can do to improve that. The first is to change my dictionary of stations from string to an int hash. I know, I know.. you might be thinking:
But wouldn’t calculating a hash cost you even more processing?
And you would be correct, dear reader, but the gains outweigh the losses on this one. The thing is that the processing loop has to check if a particular station has been already fond by searching the dictionary’s index. An integer index works so much faster than an string one that the cost of converting the station name to a hash pays out, and it pays out good!
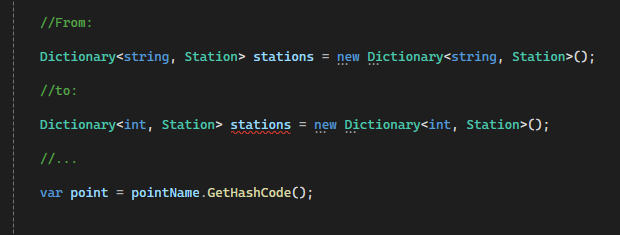
Where station is no longer a class but a struct. I changed that after reading that structs are value objects and have a smaller memory overhead than classes. The solution is now taking only 42s to complete, still some distance away from my goal of <30s, but there’s still a couple of things I can try. The next improvement was to change the standard string .readLine() and .split() with my own block. This shaved out a few more seconds, but it’s getting clear that I’m approaching the limit of my abilities. Will I be able to beat the 30s mark? (pom pom pom)!
For the win
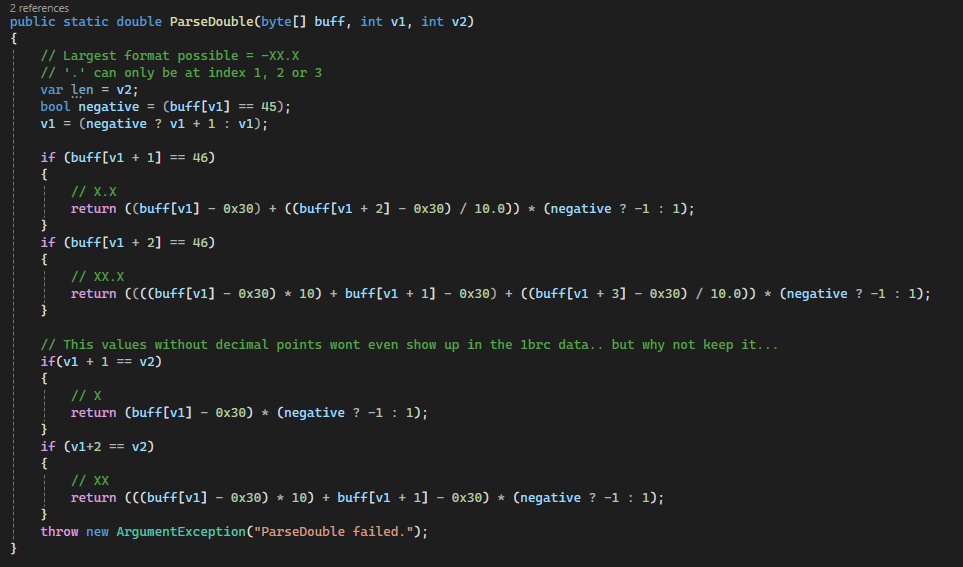
This two next improvements finally allowed my arbitrary goal to be reached. The first is quite simple, replace the double parser with a custom one. Since all numbers are in XX.X format, a simpler (and quicker) parser can be used. It looks absolutely awful and it’s extremely limited, but it does the trick quite well:
The final magic trick was changing the file stream for a MemoryMappedFile. This way each instance can create a ViewStream and read from a small buffer.
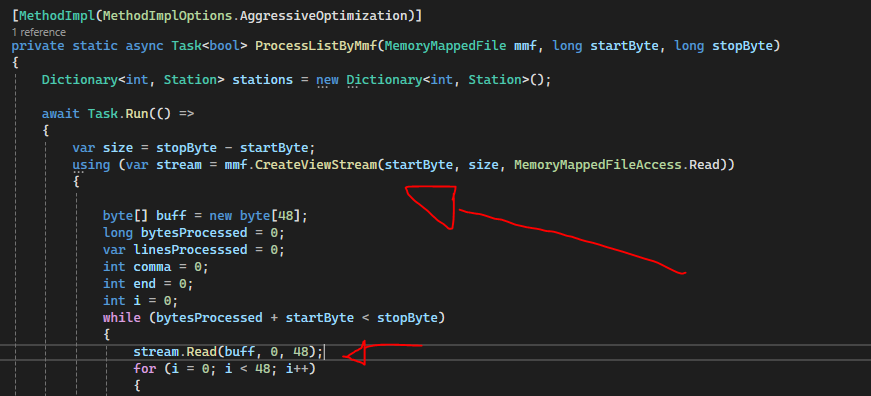
And so my final version was born! Processing the whole file in beautiful 22s on my modest Ryzen 7 3800. Surely would be even better on the challenge’s computer, which has a monstrous thread-ripper.
Final Thoughts
When my team decided to change our working language from C++ to C#, I must confess that I was a little hesitant. I wasn’t motivated to dive into the whole Microsoft world. I considered C# a sort of “java attempt”, and boy was I wrong! After 3 years I must be open and admit that C# is an extraordinary language. This little adventure sure taught me a lot about performance, and even though my solution is light years behind the champions, I’m very please to have avoided using unsafe and still completing the task in a very acceptable 22 seconds.
Thank you very much for reading theprotoblog!